【论文】深度学习CV方向论文解读
前言
本文章通过时间轴来按顺序整理CV方向的经典paper的优势和该paper对之前的改进以及个人吐槽。
每篇paper主要从网络架构和数据增强两方面来分析学习trick。
个人哔哔纯属吐槽,不具有专业性分析参考
PS:paper的时间按照arxiv最后时间为准,不代表论文最初发表时间。因为我也被弄糊涂了
后来发现要写的论文很多,都放在一篇文章不太合适不好水博客啊,以后就分开写算了,这样每篇篇幅也能更长一点。发现自己很容易就忘记之前总结的东西
Alex Net
网络
将饱和非线性神经元(tanh,sigmod)换为了非饱和非线性神经元:训练快了6倍
由于sigmod激活 ,如果hidden layer越来越小,梯度弥散,
如果前面hidden layer 越来越大,则会导致梯度爆炸。
使用LRN(local response normalization)局部响应归一化:有助于快速收敛,增加泛化能力
侧抑制(lateral inhibitio),即指被激活的神经元抑制相邻的神经元。归一化(normaliazation)的目的就是“抑制”,LRN就是借鉴这种侧抑制来实现局部抑制,尤其是我们使用ReLU的时候,这种“侧抑制”很有效 ,由于ReLU的相应结果是无界的,所以需要归一化。
LRN因为不提高准确率参数量还很多,被VGG抛弃空间池化部分:采用重叠池化(overlap pooling)
Overlap Pooling :通过设置步长s小于池化的kernel size z,重复使用平均池化,更难过拟合。
dropout:减少过拟合
算是现在很常见的一个东西了,不过有normalization layer后就没怎么用了。
数据增强
随机裁剪+镜像反射:提高准确率
通过对图像(255,255,3)四个角为中心进行随机裁剪(224,224,3)的图像,然后再水平翻转得到10张图像,通过softmax层后求precision的平均。
主成分提取PCA:减少了top-1 error 1%
在整个ImageNet训练集上对RGB像素值执行PCA。对于每幅图像加上多倍找到的主成分,大小成正比的对应特征值乘以一个随机变量,随机变量通过均值为0,标准差为0.1的高斯分布得到。
Overfeat
这篇算法没有完整的流程图,没怎么看懂怎么实现的,无法细讲。
似乎是通过回归来预测bounding box的位置?
我主要问题是加滑动窗口pool是训练集就有吗?
分类和定位是同时的话是网络再并联一个1*1卷积提取bbox参数回归?如果是这样感觉类似后面的decouple head思想。
网络
网络功能分为三个部分:分类(特征提取)、定位、检测。
滑动窗口提取特征:因为考虑后面的定位和检测,没有像AlexNet把输入图像分五份随机裁剪再水平翻转:
因为这样会打乱图片的空间特征(和以前的全连接层一样,被改进为卷积也有部分原因是强调图片空间特征),所以使用’’暴力”裁剪,stride分别为0,1,2移动,裁剪图片作为输入。这个窗口类似kernel只不过相当于裁剪?
根据前5层layer进行特征提取共享特征权重,后面接上进行分类和定位的区分全连接层。
定位:根据每个窗口裁剪出来的图片先分类,再回归bbox,预测的bbox iou<50%为FP
个人哔哔
好家伙,发现对比图里面居然有vgg,时间线被搞错乱了,难道vgg才是1*1卷积代替全连接的开山鼻祖?
注意这篇论文不是sota!这里我个人认为是由于AlexNet为网络架构(太浅了)更难提升准确率,所以文章说的时间限制应该是说没有时间尝试其他的模型。
这个类似遍历的方式裁剪图片|获取特征注定了复杂度会很高,将来会有更好的算法替代(如后篇的SS)
NIN
- 介绍了多层感知机(mutilayer perceptrons)和线性激活函数,全连接层的劣势:线性函数针对特定函数才能近似不具有通用性,全连接层太容易过拟合,可解释性低。
- 基于maxout net提出MLP conv:先在原始两个卷积层中多插入一个MLP层进行非线性提取特征,共享MLP层权重也使模型有更高的表达能力,然后在后面加个非线性函数relu。使凸函数近似变成通用函数近似。
- 提出全局平均池化GAP(global average pooling):原来的fc层因为要训练超参数容易过拟合,替换为GAP后直接取特征图的平均,也将特征图和类别联系了起来,而且没有超参数的训练,减少了过拟合和增加了模型的可解释性,还不用dropout(然后被googlenet打脸了)
个人哔哔
这篇论文是解决了fc层解释性差和fc层的过拟合问题,把卷积替换全连接怕不是借鉴了别人(感觉这篇和overfeat很像但是侧重点不同,时间线仍然错乱)。
下面解释一下为什么能够替换,参考这篇1*1 conv 介绍,和这篇mlp conv
先看如下两张图
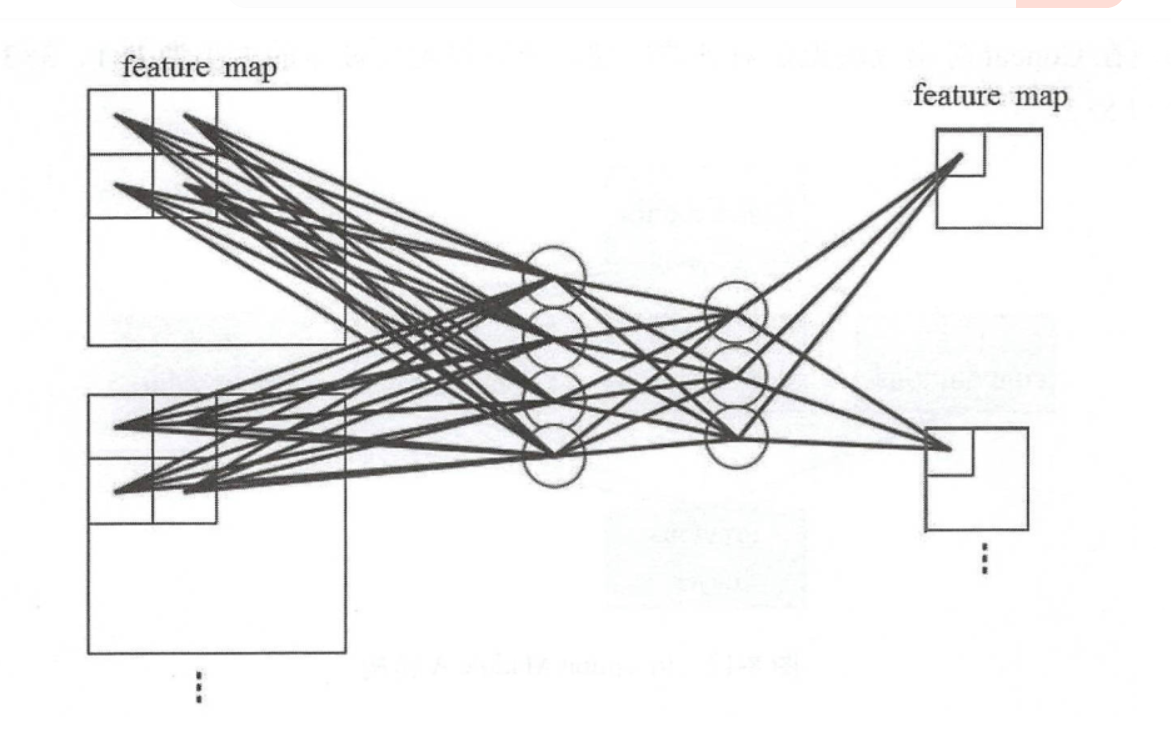
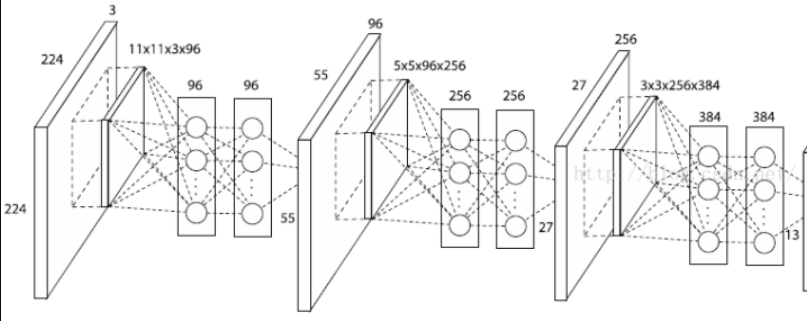
手动计算一下图二输入层数:
| No. | Intput Size | conv | stride | padding | Output Size |
|---|---|---|---|---|---|
| 1 | 224*224*3 | 11*11*96 | 4 | 3 | 55*55*96 |
| 2 | 55*55*96 | 1*1*96 | 1 | 0 | 55*55*96 |
| 3 | 55*55*96 | 1*1*96 | 1 | 0 | 55*55*96 |
由图1可见mlp conv就是加几个hidden layer 然后relu,输出和输入通道数不变,只增加了非线性性。同图2和上面推导,11卷积也可以实现上述功能,但是1\1卷积也可不只实现上述功能。
- 当1*1卷积通道数不变时+relu,则起到的是mlp conv作用。
- 当1*1卷积通道数不等于输入维度时,起到升维降维作用(降低参数量)。
- 当1*1卷积通道数等于分类数则是替代全连接层(前面一层会将输入变为1*1*channel,然后再是1*1*n_class的卷积)
RCNN
网络
提出迁移学习:在大数据集上进行有监督预训练,然后针对特定数据集进行微调(提升了8%!!!)
采样selective search算法搜索region proposal:region proposal算法包含很多种,SS算法是最受欢迎的一种之一。
Selective Search 源码分析,python源码github
非官方:- 先通过图像分隔(skimage.segmentation.felzenszwalb)将图片每一个pixel分到一个label(label是唯一的),第一次先遍历这些pixel得到区域信息,区域是矩形划分的。
- 再求出每个区域之间的texure gradient,color histogarm,region size相似度,如果区域相邻且相似则合并(相似是通过判断区域矩形是否相交)。
- 重复上述步骤。
可以看出SS是通过先分隔再不停遍历来求出BBox的,复杂度比然很高,而且图片越大越难搞
借鉴了A Deep Convolutional Activation Feature for Generic Visual Recognition把Alexnet当backbone用来提取特征的思想。
只把卷积作为提取特征的工具,最后一层分类使用的是svm,每一类都用一个svm。
分类的时候不光分类了种类,还将背景单独分了一类。(如今的two filter的启发可能来于这)
困难负样本挖掘(hard negative mining):因为detect会有很多负样本,正负样本不均衡。
这也是目标识别的一大通病,所以要增加负样本的’’质量’’ 。hard negative就是每次把那些顽固的棘手的错误,再送回去继续练,练到你的成绩不再提升为止.这一个过程就叫做’hard negative mining.具体可以参考知乎
使用不同网络做backbone效果会有差别,把VGG和AlexNet对比:map增加了8%,训练时间长了7倍。
数据处理
先固定图像尺寸为500pixels,然后再输入到ss算法中
由于backbone为AlexNet,ss的输出大小都是不同的要将图像变为224*224的大小输入,scale采用的方法如下:
- tightest square with context:是指在原始图像上找到这样一个可以包含整个proposal 的最小的正方形,然后将这个正方形 rescale 为卷积网络可以接受的尺寸
- tightest square without context
- warp:直接rescale到输入尺寸
个人哔哔
提出预训练和backbone的思想,region proposal使用ss提取,算法复杂度注定了还有改进空间,svm分类后来也被换为了卷积。然后就是hard negative mining 不会过拟合吗。
论文说和overfeat很相似,但是overfeat是rcnn的特例,只是RCNN是每一类用svm分离和每一类都有一个bbox的回归
这几篇代码都是matlab或C++写的,我刚好就是看不惯matlab。 matlab果然是上个时代的产物
Google Net
网络
在1*1卷积降维基础上为了保留压缩信息提出了deep concat。
NIN 说GAP可以不用dropout,但是googlenet网络最后还是用了。
目标检测方面借鉴了RCNN的SS搜索:
突然看到RCNN猝不及防通过ensemble 6个ConvNets 对每个proposal region进行分类,提高了近4个百分点,但是由于时间原因使用Bounding box回归。
个人哔哔
个人觉得提出了deep concat是一个很好的创新点,因为每一个新的网络模型都能带来不同的思想方向,比如说后面的dw卷积说没有受到这篇的启发是不可能的。
从这篇也看到了1*1卷积应用广泛,后面就不再单独提这个了
FCN
个人哔哔
如果目前时间顺序是对的话,个人感觉这篇没什么,全连接用卷积替代早在前面几篇就有所端倪了,不过是整合并证明了一下。也可能是我理论基础不太行,看不懂毕竟这篇几乎算图像分割的开山之作了
但是文章中出现了新词patch-wise(虽然文中说也可以不用patch-wise):这篇stackoverflow关于patch-wise回答的挺好,可以看看:
术语“Patchwise ”旨在避免完整图像训练的冗余。在语义分割中,假设您对图像中的每个像素进行分类,通过使用整个图像,您在输入中添加了大量冗余。在训练分割网络期间避免这种情况的标准方法是从训练集中向网络提供批量随机补丁(感兴趣对象周围的小图像区域)而不是完整图像。这种“逐块采样”确保输入具有足够的方差并且是训练数据集的有效表示(小批量应该与训练集具有相同的分布)。这种技术还有助于更快地收敛并平衡类。在这篇论文中,他们声称没有必要使用 patch-wise 训练,如果你想平衡类,你可以对损失进行加权或采样。从另一个角度来看,逐像素分割中的全图像训练的问题在于输入图像具有很多空间相关性。要解决此问题,您可以从训练集中采样补丁(patchwise 训练)或从整个图像中采样损失。这就是为什么该小节被称为“Patchwise training is loss sampling”。因此,通过“将损失限制为其空间项的随机采样子集,可以从梯度计算中排除补丁。”他们通过随机忽略最后一层的单元来尝试这种“损失采样”,因此不会在整个图像上计算损失。
VGG
网络
吸收Alexnet经验,激活层全部换成relu。
大部分没有使用LRN(只用了一层):在imagenet 准确率没有提高,还带有很高的参数。
更多的使用更小的卷积(3*3):减少参数量的同时使网络更深,表达能力更强。
两个3*3卷积感受野与一个5*5 卷积相同,三个3*3卷积感受野与7*7相同,但是相比之下用更小的卷积核参数量更少。而且两个3*3卷积强迫7*7卷积分开,中间的非线性激活相当于之前的正则化层。
使用1*1卷积:与线性层本质和效果相同,起到代替全连接层,更快的运算的效果。
空间池化部分:没有使用平均池化,全部使用最大池化层。
数据增强
- 随机采样+镜像翻转
- 没有像AlexNet用PCA,而是图像减去rgb平均值来消除光照影响。
个人哔哔
单从论文写作的角度来说VGG与AlexNet没有说每一步trick增加的准确率,所以个人认为VGG更多的是网络架构优势:小卷积多卷。而不是池化等trick。ILSVRC以top-5 error 6.8%排第二也是惨,被谷歌截胡了。
感受野确实很难理解,下面简单介绍一下,具体意义可以参考这篇
感受野计算公式:
第一层感受野为kernel size,即$RF_0$=1 ,由上可见该层感受野与该层stride无关
输出层size计算公式:
其实这两个公式是卷积和反卷积的过程,本质是相同的。
感受野是从最后一层向上逆推,输出size则是从输入向下正推。
| No. | Layer | input size | kernel size | stride | padding | output size | Receptive Field(感受野) |
|---|---|---|---|---|---|---|---|
| 1 | conv | 28*28 | 3*3 | 1 | 0 | 26 | 3 |
| 2 | conv | 24*24 | 3*3 | 1 | 0 | 24 | 5 |
| 3 | conv | 22*22 | 3*3 | 1 | 0 | 22 | 7 |
| 4 | conv | 20*20 | 3*3 | 1 | 0 | 20 | 9 |
| 5 | conv | 18*18 | 3*3 | 1 | 0 | 18 | 11 |
| 1 | conv | 28*28 | 5*5 | 2 | 1 | 24 | 5 |
| 1 | conv | 28*28 | 7*7 | 2 | 1 | 22 | 7 |
| 1 | conv | 28*28 | 11*11 | 4 | |||
Unet
网络
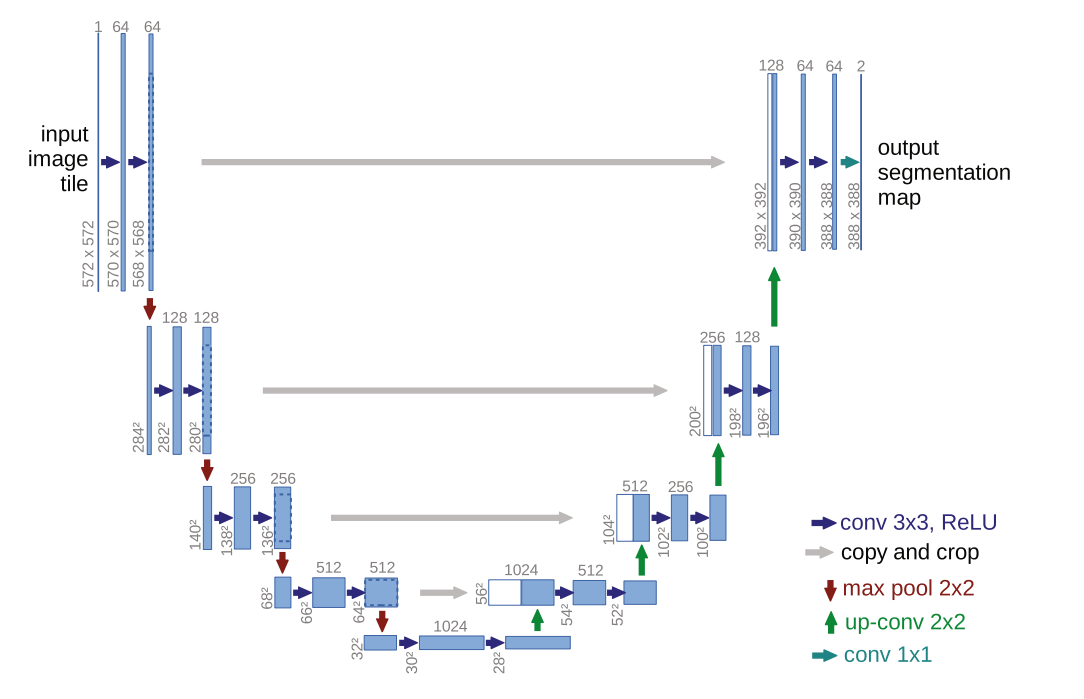
这个网络很简单,无非就是卷卷卷,然后concat。论文中有几点不是很方便:
每次下采样的时候长宽维度会减小,concat的时候就会需要中心裁剪(示意图片中的虚线部分)然后再concat
最后生成的图片维度可以发现与原图片维度不同,这就代表输入图片不能简单的按patch输入还需额外处理,原文中是使用镜像来解决的。这里解释一下patch:
通常一张超大图片都是分割成一张张小图片输入的(显存不够输入一张大图片),并且每张图片直接会有重叠(overlap),以防边缘信息不被利用。
需要注意的是论文他没有使用padding,并且后面大火的batch normalization才刚出,论文中也没有使用。上采样采用的是转置卷积而不是现在常用的双线性插值。
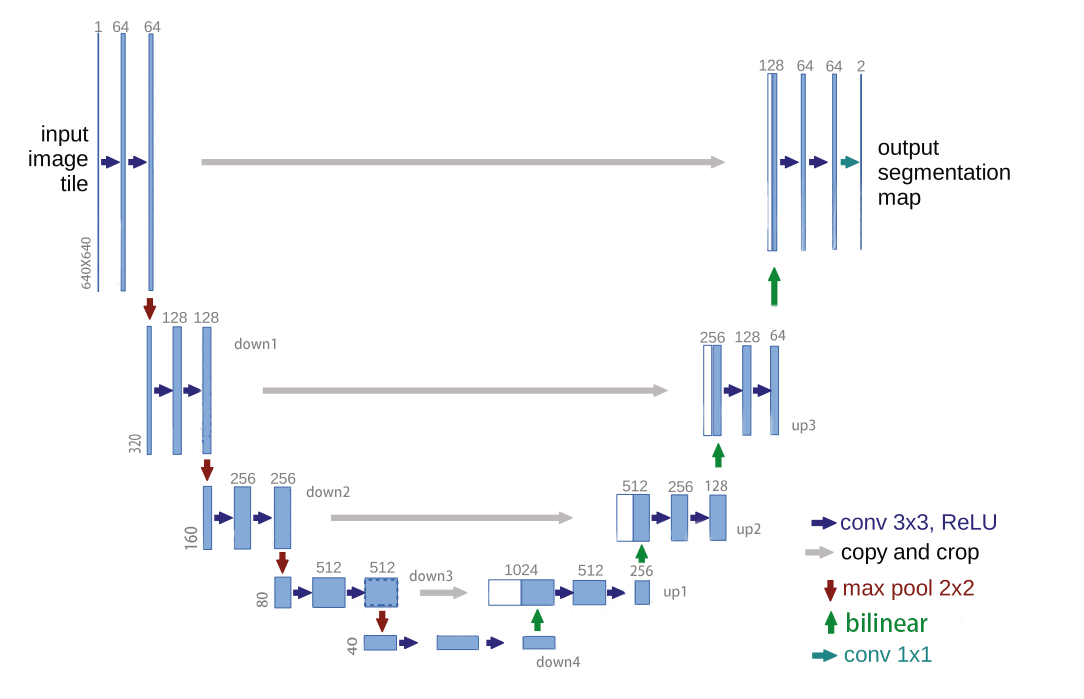
现在大家通常修改了卷积层下采样的部分:增加padding使卷积后尺寸不变,也不用crop了。然后在卷积和relu直接加上BN层。并且用双线性插值代码更好写且效果还变强了,当然自己魔改也可
修改后的网络维度如下图(输入维度随便写的):
dice loss
数据增强
“当只有很少的训练样本可用时,数据增强是网络所需的不变性和鲁棒性的关键。我们需要的是旋转不变性,以及对变形和灰色值变化的鲁棒性。特别是训练样本的随机弹性变形似乎是训练分段的关键概念”然而只是简单的使用随机位移向量处理了一下。
个人哔哔
看到这个网络肯定有人会比较和FCN的区别,但是FCN相当于分割的开山鼻祖相似也没办法我也觉得没什么大区别。细节还是有的:
- fcn没有解决大图片的问题(我感觉这只是需求不同导致的,毕竟医学图像都很大)
- fcn尺度不够多,只是一个尺度卷卷卷,没有使用FPN的想法。
ResNet
网络
完全去掉了LRN、dropout,并采用BN(batch normalization)层替代:标准化,可以增强表达能力,防止过拟合。
想象一个sigmod激活,当数据范围分布差异很大时,sigmod激活不能很好的表现出数据的差异,就像轻轻打你一拳和重重打你一拳感觉差不多,这是很糟糕的情况。batch normalization通过均值方差标准化能够很好的处理这种情况,并且最后还会scale shift 还原。BN层具体作用看这篇
增加残差结构:修正了深网络的梯度的问题。
残差结构的好处就是,实现了一个恒等变换$h(x)=x$,这个恒等变换实际上是一个网络的目标函数,但是由于网络越深,虽然表达能力越强,但是梯度弥散和爆炸问题明显。所以本质上是解决梯度弥散和爆炸问题。可以理解为之前论文的加强正则化效果。
数据增强
直接就把AlexNet和VGG结合了
采用和AlexNet相同的数据增强方法:随机在图片里选取224*224大小图片,再镜像翻转。
采用和VGG相同的光照影响方法:减去rgb平均值
The image is resized with its shorter side randomly sampled in [256, 480] for scale augmentation. A (224, 224) crop is randomly sampled from an image or its horizontal flip, with the per-pixel mean subtracted.
先依照短边随机缩放,然后再224*224采样,随机镜像翻转,最后减去rgb均值。
pytorch实现与原文有点不一样,注意一下。具体pytorch实现细节可以参考这篇
使用10-crop test,提高准确率
个人哔哔
2015 ILSVRC top-5 error 3.57%,直接拿第一。说明了残差网络确实nb,也算是解决了深度层网络的根本问题(梯度问题|恒等变换)。
Transformer
论文解读
原论文讲解的还是比较粗略,还是得看别人的讲解和图片,强烈推荐这篇,我个人觉得我对attention还是理解不够,还不能写自己的理解。
一些问题
为什么使用muti head
关于different representation subspaces,举一个不一定妥帖的例子:当你浏览网页的时候,你可能在颜色方面更加关注深色的文字,而在字体方面会去注意大的、粗体的文字。这里的颜色和字体就是两个不同的表示子空间。同时关注颜色和字体,可以有效定位到网页中强调的内容。使用多头注意力,也就是综合利用各方面的信息/特征。
pos embed是怎么实现的
attention为什么要加scaled
数量级对softmax得到的分布影响非常大。在数量级较大时,softmax将几乎全部的概率分布都分配给了最大值对应的标签
某个值很大时,其余都会很接近0(onehot 向量),上式也就会很趋近于0。
所以对于如果多层堆叠
令z=qk则有:
可知,当head_dim越大时方差越大,则最大值与最小值差距越大,就导致了上述的softmax梯度消失问题。
为将方差变为1,故self-attention公式如下
此时
为什么平常softmax并没有这一步呢?
平常都是最后一层增加softmax,这时输出信号与我们需要的信号相差无几不用scale
attention有add和muti,add需要scale吗?
根据论文Massive Exploration of Neural Machine Translation Architectures,由于add是由tanh激活映射到[-1,1],方差一般会在1之内,但是维度过大时(1000以上时)也需要scale。
个人哔哔
我之前一直以为attention 和transformer是一个东西两个名字,好长一段后才知道这两个东西不一样…就和resnet与shortcut关系相似。attention只是transformer架构里的一个小模块。并且这个小模块还包含很多不同名的attention
在此之前nlp迫于时间序列都是基于lstm,rnn在研究,attention机制出来之后,不仅解决了lstm,rnn并行计算的缺陷,还提出了一种全新的思想架构transformer,使不需要cnn,rnn也能有很好的效果。之后的vit,swin transformer甚至将nlp领域转移到图像分类领域,也体现了attention机制的泛用性,也算是机器学习的一个大变革了。谷歌还是nb
但是随之影响到的肯定是我们这批穷鬼,attention的矩阵计算机制是通过全连接实现的(还记得线性回归吗,全连接就是矩阵相乘),参数量爆炸,没及几张好卡根本跑不动。比谁卡多的时代终究来临
代码实现的时候发现要加载预训练权重必须按照官网的名称写,还要手写attention…,麻烦但很有收获。要注意一点,dropout rate全部都是0,如果不小心传入了默认参数验证集准确率可能会降低(很玄学,不过我也就在小数据集上训练了一个epoch,不代表广泛性仅个人记录)
YoloX
网络
(目前这些我没具体学,就不介绍了)
大致讲解见知乎这篇
- Anchor free:
可以参考这篇 - SimOTA:
- Muti positive
- End-to-end Yolo
数据增强
可以参考这篇
- Mosaic
- Mix up
加了这两个trick可以多2.9%AP就恐怖,赶快学着用起来。
个人哔哔
感觉是钻Yolo的空子,全篇都是各种trick,最后还说由于时间原因没有加最近transformer的成果trick,真是争分夺秒。个人觉得这篇文章基本上可以算是一篇综述了,因为我从这参考文献递归知道了许多论文,是不是和综述paper效果一样。那我这篇不就是综述的综述了,害怕
不过能把别人的网络改成暂时的sota也是一种本事。代码能力极强,像我这水平现在写个网络都不知道能不能写对
To be Continued
本文链接:https://dummerfu.top/p/61340.html
版权声明: 本博客所有文章除特别声明外,均采用CC BY-NC-SA 4.0许可协议 转载请注明出处!







