【数模】从入门到入土
第一讲 模糊数学聚类基础
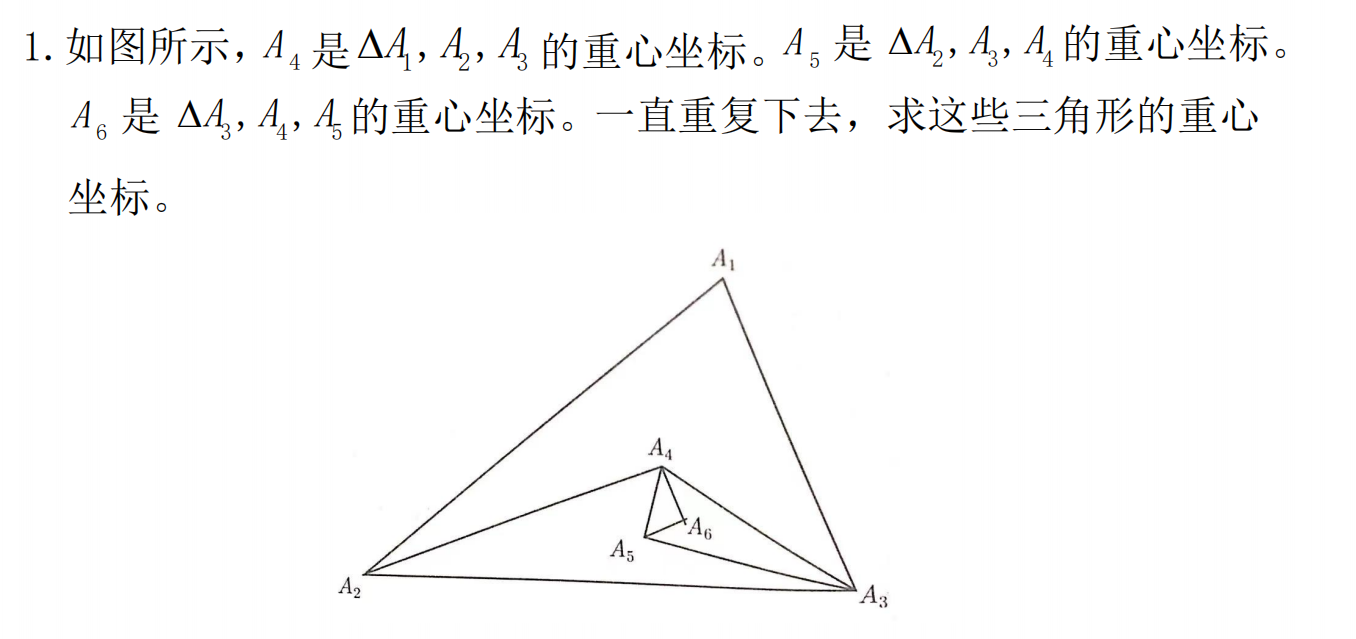
练习 1

更普遍性的解肯定不能通过线性相关性来判定,思考模糊聚类。
通过题目数据可以得到一个矩阵方程组。常规归一化就有一个模糊矩阵,然后再通过格贴近度得到模糊相似矩阵,最后计算传递闭包求得模糊等价矩阵从而推出聚类关系。即可判断哪些气象站差别不大可删去。
PS: 模糊相似矩阵可以通过多种方法求得,不细讲了,通常有:
指数相似度法
最大值最小法
几何平均法
绝对值倒数法
数量积法
夹角余弦法
相关系数法
一般越复杂越nb
import numpy as np |
并查集优化结果:
class Unit_find(object): |
第二讲 排队论
练习
某店有一个修理工人,顾客到达过程为Poisson流,平均每小时3人,修理时间服从负指数分布,平均需10分钟,求:
店内空闲的时间;
有4个顾客的概率;
- 至少有一个顾客的概率;
- 店内顾客的平均数;
- 等待服务的顾客数;
- 平均等待修理的时间;
- 一个顾客在店内逗留时间超过15分钟的概率
啥也不会,跟着zzy抄就完事了
此题满足排队论里的 $M|M|1|\infty|\infty$模型
- 店里空闲时间$P_0=0.05$
- 四个顾客概率$p_4=\rho^4(1-\rho)=0.5^5$
- 至少有一个顾客的概率$p_{n\geq1}=1-p_0=0.95$
- 店内顾客平均人数$L_s=\frac{\lambda}{\mu-\lambda}=1$
- 等候服务顾客人数$L_q=L_s-(1-p_0)=0.05$
第三、四讲 简单图论
练习

题意有点奇怪,理解有两种题意:
- 疑问:因为有4-5年的维修费意思是买来就要付第一年的维修费?
黑心 - 题意1:维修费与机器使用时间有关,逐年递增比如维修三年需要(5+6+8)。
- 题意2:维修费用和机器使用时间无关,只与每年行情有关,第一年买的机器和第四年买的机器都只需要18的维修费。
如果题意1:可以从当前点向前分别连接5条边,权值分别为 [5,11,19,30,48] ,然后逐年连 [11,11,12,12,13]的边权,建图跑1-5的最短路就行了。
如果题意2:感觉和最短路没什么关系了,直接贪心?
因为要求是用最短路解决,所以我默认是题意1
from queue import PriorityQueue |
第五讲 方差分析
练习 1
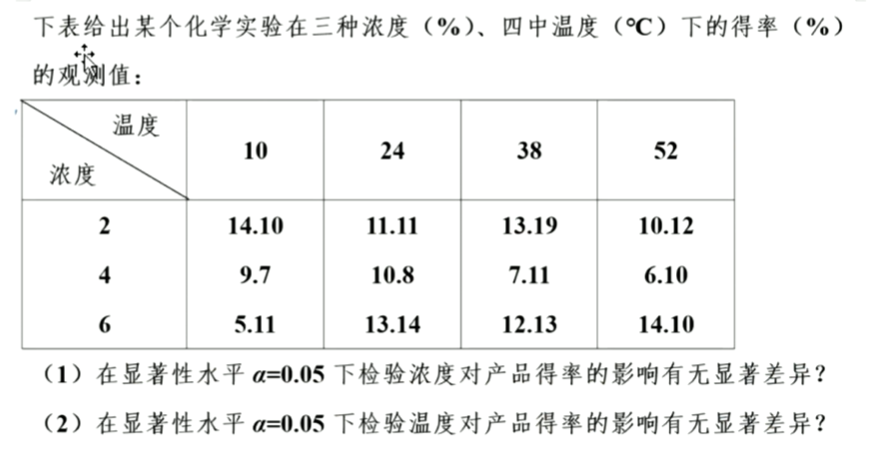
就是一个显著性检验,SPSS分析就完事了。概率论全忘光,
第六讲 机器学习
ppt乱死了,也没看到他有作业 😥。
第七讲 整数规划
练习 1
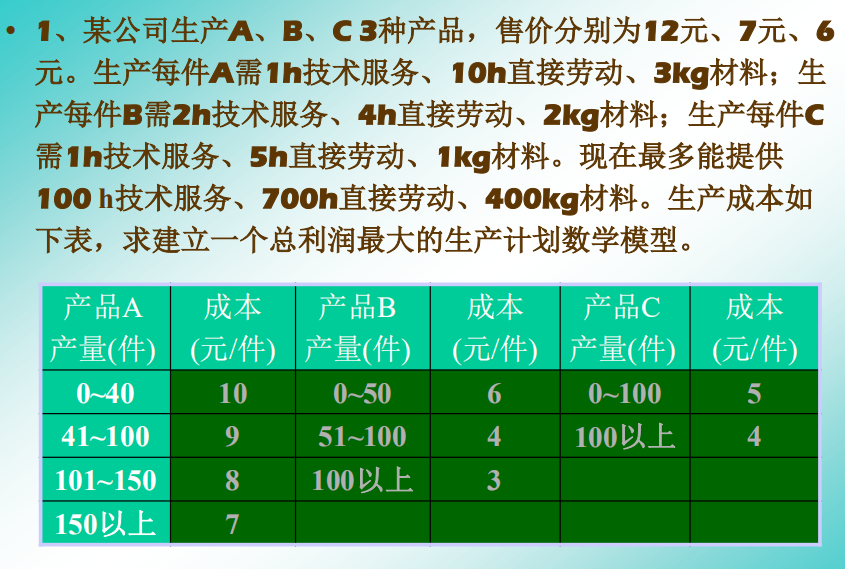

import numpy as np |
练习 2
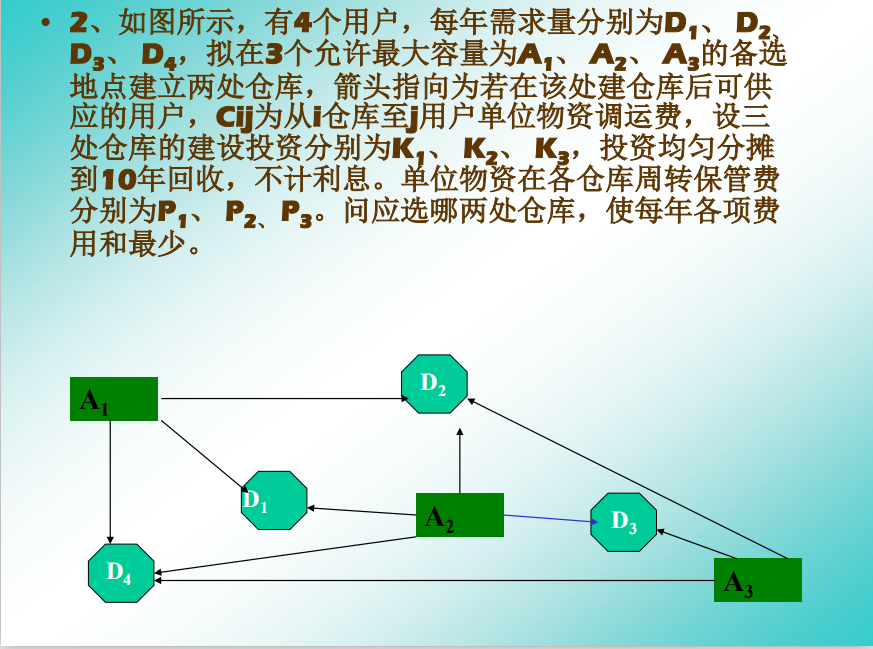

方便起见都设为1好了,就是一个整数01线性规划。
import numpy as np |
第八讲 BP神经网络
无作业 撞专业了导致看ppt有莫名的感觉 😒
第九讲 多目标优化
多目标优化的性能度量
标准:
- 必须收敛到pareto 优解集
- pareto优解集的均匀性和稳定性
反映了一个算法得到的最优解被另一个算法得到的最优解支配的比例。设 A 和 B 分别是算法 A 和算法 B 得到的非支配解集或 Pareto 最优解集:
其中 |B|表示集合 B中的元素个数,a covers b表示a支配b或a与b同样好。
若C(A,B)>C(B,A),则算法 A 求得的 Pareto 最优解集优于算法 B 求得的 Pareto 最优解集。
为测量 A 的均匀性和宽广性,设 $P^\star$是Pareto 前沿面上均匀分布的一组解,$P^\star$到 A的平均距离定义为:
d(v,A)表示v与A中的点的最小欧式距离, $D(A,P^\star)$越小,说明A 越接近 Pareto 前沿面
练习 1
遗传算法yyds

设生产$x_0$,$x_1$个A,B型号润滑油,分别加工生产$x_3$,$ x_4$个A,B型号润滑油,观察题目数据,发现必须会有加工生产。
这里使用的是Geatpy库实现,不同库的对比可以参考这篇知乎自行选择
import numpy as np |

练习 2
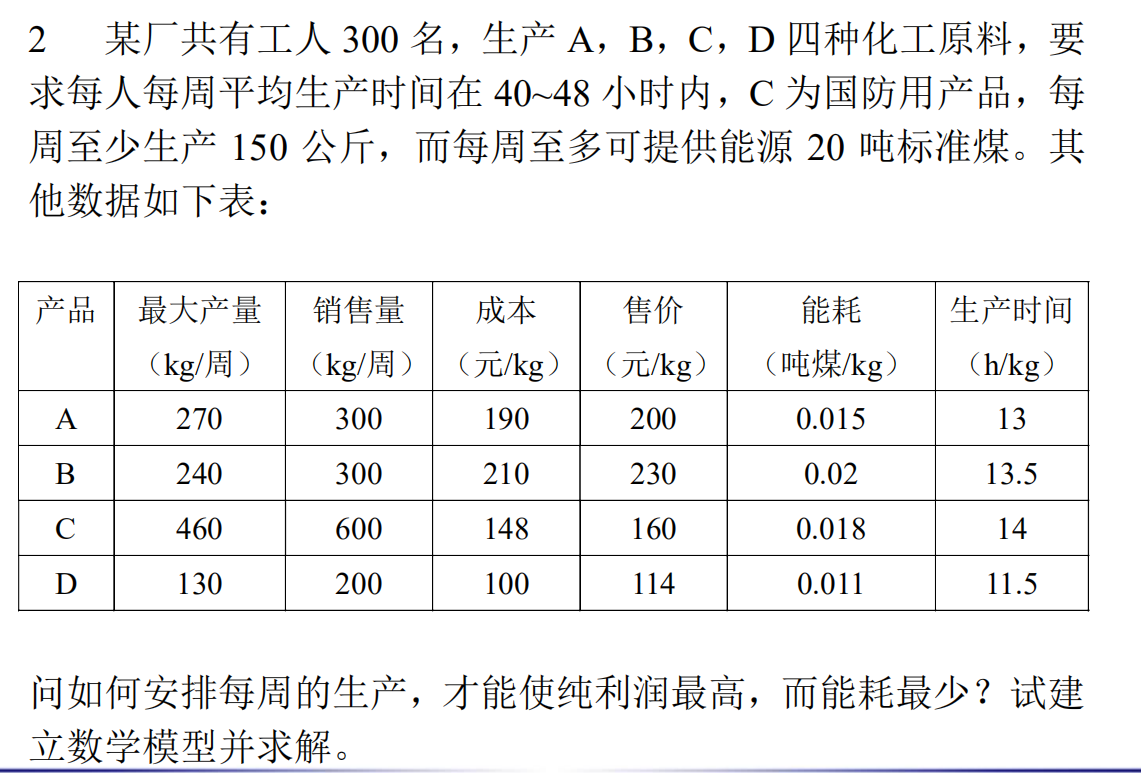
由题意可建得以下模型:
import numpy as np |

第十讲 过程预测与优化
好家伙,全英文ppt,头看掉了
第十一讲 时间序列分析
似乎没有作业,全程讲课 时间序列的学习我之前写过这一篇
第十二讲 马氏链模型
练习

每天的状态转移规律
因为$X_{n+1} \in [1,2,3,4,5]$,所以概率矩阵为
以此类推可得完整状态转移矩阵P
第十三讲 蒙特卡洛模拟
蒙特卡洛还是比较重要的,就多来几道例题吧
了解随机数

# 读懂了就很简单了 |
例题


好家伙python光循环1e6次并且里面生成随机数就无了,亏我还用的是的numpy.random
果然这种暴力还是c++更适合
import numpy as np |
有没有大佬传授一下提速的奇淫技巧啊
练习
用计算机仿真布沣实验计算圆周率。

显然,答案与针的横坐标无关,一个针的坐标位置只与纵坐标y和角度$\theta$ 有关。
设距最近下面的横线距离为y显然$y\in [0,a)$的均匀分布且$\theta \in [0,\pi)$的均匀分布,相交只需判断$y+lsin(\theta)>ceil$ 和 $y-lsin(\theta)<floor$即可。
概率公式如下:
import numpy as np |
第十四讲 1stopt
看到这图…. 散了散了,不会有人20世纪了还在这学passcal吧,basic就离谱
散了散了,不会有人20世纪了还在这学passcal吧,basic就离谱
但是练习还是要做的
练习
最小二乘法拟合曲线…也没什么技术含量。
函数长这样:
在作业data中,w表示自变量,也是excel的第一列,第二和第三列分别表示因变量的实部和虚部。
要求:第一,采用最小二乘法进行拟合;
第二,在已知函数的时候,求几个参数的最优值。
第十五讲 数值计算方法
第十六讲 常微分方程模型
练习 1

第十七讲 差分方程模型
都是数学题,压根不用码,靠zzy带飞 orz
练习 1
特征方程解得$\lambda_{1,2,3}=\frac{\pm\sqrt2j -1}{3}$所以
$C_1 ,C_2,C_3$由$x_1,x_2,x_3$初始值可解出
练习 2

将上面三个差分方程整合可得有:
求得特征方程为:
根据求根公式可得解,通过控制所有解绝对值小于1可令群体负增长
练习 3

列得关系式:
不动点:
收敛极限:
练习 4

易得:
第十八讲 偏微分方程模型
作业太随便了,就是做往年题
第十九讲 微分方程模型数值解
第二十讲 2020国赛C题
- 使用模型方法前要解释为什么要使用这个方法,比如为什么要使用回归?分类?
- 求解优化问题时要先介绍求解方法和过程,有必要可以画流程图。
- 每一个求解结果都需要用图标直观显示,并说明与之前的对比。
- 大型的神经网络模型只需要把与题目相关的解释清楚,但是随篇幅灵活改动。
- 没有数据的问题可以从网上爬取。
- 附代码必须写注释
虽然估计也没人看 - 写论文前可以参考知网、万方,但是不要盲目相信,因为国内论文水平可能很低,即使是硕士论文
- 要明确解决问题的目标,然后寻找论文或算法,不要盲目跟随别人的论文。
- 参考文献,一般在问题分析里面引用参考文献,因为你不是从头开始求解这个问题的
- 参考文献即使是链接也可以引用,但是需要说明链接的主要内容
- 参考文献必须要在正文引用。
第二十一讲 博弈论和纳什均衡
练习

看这个ppt才明白纯策略纳什均衡

纯策略纳什均衡为 工人不偷懒,监工不监督
混合策略纳什均衡:
设监工监督的概率为P,不监督的概率为1-P
则在混合策略纳什均衡条件下,监工监督概率为0.5,此时工人的收益为 (1-1)P=0
第二十二讲 数值计算分析
无作业
第二十三讲 反应扩散方程
练习

第二十四讲 工程数学建模
无作业,看都不想看
END
本文链接:https://dummerfu.top/p/50102.html
版权声明: 本博客所有文章除特别声明外,均采用CC BY-NC-SA 4.0许可协议 转载请注明出处!






