import math
from draw_box_utli import draw_box
from torch.utils.data import Dataset
from VocDataset import VocDataSet
import matplotlib as mpl
import random
import cv2
import numpy as np
from matplotlib import pyplot as plt
mpl.rcParams['font.sans-serif'] = 'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
def get_mosaic_coordinate(mosaic_image, mosaic_index, xc, yc, w, h, input_h, input_w):
if mosaic_index == 0:
x1, y1, x2, y2 = max(xc - w, 0), max(yc - h, 0), xc, yc
small_coord = w - (x2 - x1), h - (y2 - y1), w, h
elif mosaic_index == 1:
x1, y1, x2, y2 = xc, max(yc - h, 0), min(xc + w, input_w * 2), yc
small_coord = 0, h - (y2 - y1), min(w, x2 - x1), h
elif mosaic_index == 2:
x1, y1, x2, y2 = max(xc - w, 0), yc, xc, min(input_h * 2, yc + h)
small_coord = w - (x2 - x1), 0, w, min(y2 - y1, h)
elif mosaic_index == 3:
x1, y1, x2, y2 = xc, yc, min(xc + w, input_w * 2), min(input_h * 2, yc + h)
small_coord = 0, 0, min(w, x2 - x1), min(y2 - y1, h)
return (x1, y1, x2, y2), small_coord
def random_perspective(
img,
targets=(),
degrees=10,
translate=0.1,
scale=0.1,
shear=10,
perspective=0.0,
border=(0, 0),
):
height = img.shape[0] + border[0] * 2
width = img.shape[1] + border[1] * 2
C = np.eye(3)
C[0, 2] = -img.shape[1] / 2
C[1, 2] = -img.shape[0] / 2
R = np.eye(3)
a = random.uniform(-degrees, degrees)
s = random.uniform(scale[0], scale[1])
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
S = np.eye(3)
S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180)
S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180)
T = np.eye(3)
T[0, 2] = (
random.uniform(0.5 - translate, 0.5 + translate) * width
)
T[1, 2] = (
random.uniform(0.5 - translate, 0.5 + translate) * height
)
M = T @ S @ R @ C
if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any():
if perspective:
img = cv2.warpPerspective(
img, M, dsize=(width, height), borderValue=(114, 114, 114)
)
else:
img = cv2.warpAffine(
img, M[:2], dsize=(width, height), borderValue=(114, 114, 114)
)
n = len(targets)
if n:
xy = np.ones((n * 4, 3))
xy[:, :2] = targets[:, [0, 1, 2, 3, 0, 3, 2, 1]].reshape(
n * 4, 2
)
xy = xy @ M.T
if perspective:
xy = (xy[:, :2] / xy[:, 2:3]).reshape(n, 8)
else:
xy = xy[:, :2].reshape(n, 8)
x = xy[:, [0, 2, 4, 6]]
y = xy[:, [1, 3, 5, 7]]
xy = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
xy[:, [0, 2]] = xy[:, [0, 2]].clip(0, width)
xy[:, [1, 3]] = xy[:, [1, 3]].clip(0, height)
i = box_candidates(box1=targets[:, :4].T * s, box2=xy.T)
targets = targets[i]
targets[:, :4] = xy[i]
return img, targets
def box_candidates(box1, box2, wh_thr=2, ar_thr=20, area_thr=0.2):
w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
ar = np.maximum(w2 / (h2 + 1e-16), h2 / (w2 + 1e-16))
return (
(w2 > wh_thr)
& (h2 > wh_thr)
& (w2 * h2 / (w1 * h1 + 1e-16) > area_thr)
& (ar < ar_thr)
)
def adjust_box_anns(bbox, scale_ratio, padw, padh, w_max, h_max):
bbox[:, 0::2] = np.clip(bbox[:, 0::2] * scale_ratio + padw, 0, w_max)
bbox[:, 1::2] = np.clip(bbox[:, 1::2] * scale_ratio + padh, 0, h_max)
return bbox
class MasaicDataset(Dataset):
def __init__(
self, dataset, input_size=(640,640),mosaic=True, preproc=None,
degrees=10.0, translate=0.1, mosaic_scale=(0.5, 1.5),
mixup_scale=(0.5, 1.5), shear=2.0, perspective=0.0,
enable_mixup=True, mosaic_prob=1.0, mixup_prob=1.0, *args
):
"""
Args:
dataset(Dataset) : Pytorch dataset object.
img_size (tuple):
mosaic (bool): enable mosaic augmentation or not.
preproc (func):
degrees (float):
translate (float):
mosaic_scale (tuple):
mixup_scale (tuple):
shear (float):
perspective (float):
enable_mixup (bool):
*args(tuple) : Additional arguments for mixup random sampler.
"""
self._dataset = dataset
self.input_dim=input_size
self.preproc = preproc
self.degrees = degrees
self.translate = translate
self.scale = mosaic_scale
self.shear = shear
self.perspective = perspective
self.mixup_scale = mixup_scale
self.enable_mosaic = mosaic
self.enable_mixup = enable_mixup
self.mosaic_prob = mosaic_prob
self.mixup_prob = mixup_prob
def __len__(self):
return len(self._dataset)
def __getitem__(self, idx):
if self.enable_mosaic and random.random() < self.mosaic_prob:
mosaic_labels = []
input_h, input_w = self.input_dim[0], self.input_dim[1]
yc=640
xc=640
indices = [idx] + [random.randint(0, len(self._dataset) - 1) for _ in range(3)]
for i_mosaic, index in enumerate(indices):
img, target = self._dataset.pull_item(index)
_labels=target['labels']
h0, w0 = target['image_info']
scale = min(1. * input_h / h0, 1. * input_w / w0)
img = cv2.resize(
img, (int(w0 * scale), int(h0 * scale)), interpolation=cv2.INTER_LINEAR
)
(h, w, c) = img.shape[:3]
if i_mosaic == 0:
mosaic_img = np.full((input_h * 2, input_w * 2, c), 114, dtype=np.uint8)
(l_x1, l_y1, l_x2, l_y2), (s_x1, s_y1, s_x2, s_y2) = get_mosaic_coordinate(
mosaic_img, i_mosaic, xc, yc, w, h, input_h, input_w
)
mosaic_img[l_y1:l_y2, l_x1:l_x2] = img[s_y1:s_y2, s_x1:s_x2]
padw, padh = l_x1 - s_x1, l_y1 - s_y1
labels = _labels.copy()
if _labels.size > 0:
labels[:, 0] = scale * _labels[:, 0] + padw
labels[:, 1] = scale * _labels[:, 1] + padh
labels[:, 2] = scale * _labels[:, 2] + padw
labels[:, 3] = scale * _labels[:, 3] + padh
mosaic_labels.append(labels)
if len(mosaic_labels):
mosaic_labels = np.concatenate(mosaic_labels, 0)
np.clip(mosaic_labels[:, 0], 0, 2 * input_w, out=mosaic_labels[:, 0])
np.clip(mosaic_labels[:, 1], 0, 2 * input_h, out=mosaic_labels[:, 1])
np.clip(mosaic_labels[:, 2], 0, 2 * input_w, out=mosaic_labels[:, 2])
np.clip(mosaic_labels[:, 3], 0, 2 * input_h, out=mosaic_labels[:, 3])
mosaic_img, mosaic_labels = random_perspective(
mosaic_img,
mosaic_labels,
degrees=self.degrees,
translate=self.translate,
scale=self.scale,
shear=self.shear,
perspective=self.perspective,
border=[-input_h // 2, -input_w // 2],
)
if (
self.enable_mixup
and not len(mosaic_labels) == 0
and random.random() < self.mixup_prob
):
mosaic_img, mosaic_labels = self.mixup(mosaic_img, mosaic_labels, self.input_dim)
img_info = (mosaic_img.shape[1], mosaic_img.shape[0])
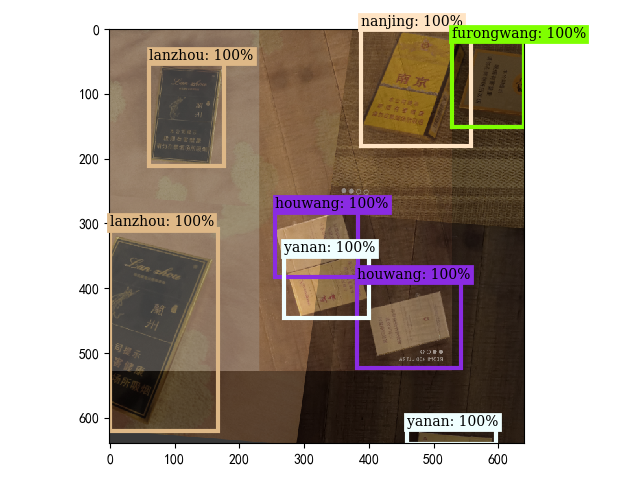
draw_box(
mosaic_img, mosaic_labels[:, :4],
classes=mosaic_labels[:, -1],
category_index=self._dataset.num2name,
scores=np.ones(shape=(len(mosaic_labels[:, -1]))),
thresh=0
)
return mosaic_img, mosaic_labels,img_info
else:
img, target = self._dataset.pull_item(idx)
return img, target
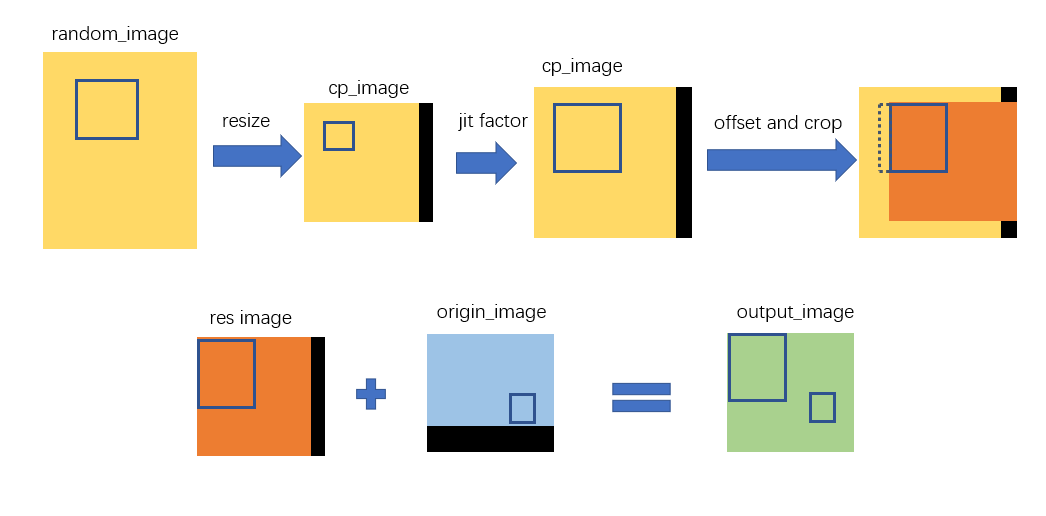
def mixup(self, origin_img, origin_labels, input_dim):
jit_factor = random.uniform(*self.mixup_scale)
FLIP = random.uniform(0, 1) > 0.5
cp_labels = []
img=None
while len(cp_labels) == 0:
cp_index = random.randint(0, self.__len__() - 1)
img,target = self._dataset.pull_item(cp_index)
cp_labels=target['labels']
draw_box(img,cp_labels[:,:4],cp_labels[:,-1],self._dataset.num2name,scores=np.ones(len(cp_labels[:,-1])))
if len(img.shape) == 3:
cp_img = np.ones((input_dim[0], input_dim[1], 3), dtype=np.uint8) * 114
else:
cp_img = np.ones(input_dim, dtype=np.uint8) * 114
cp_scale_ratio = min(input_dim[0] / img.shape[0], input_dim[1] / img.shape[1])
resized_img = cv2.resize(
img,
(int(img.shape[1] * cp_scale_ratio), int(img.shape[0] * cp_scale_ratio)),
interpolation=cv2.INTER_LINEAR,
)
cp_img[
: int(img.shape[0] * cp_scale_ratio), : int(img.shape[1] * cp_scale_ratio)
] = resized_img
cp_img = cv2.resize(
cp_img,
(int(cp_img.shape[1] * jit_factor), int(cp_img.shape[0] * jit_factor)),
)
cp_scale_ratio *= jit_factor
if FLIP:
cp_img = cp_img[:, ::-1, :]
origin_h, origin_w = cp_img.shape[:2]
target_h, target_w = origin_img.shape[:2]
padded_img = np.zeros(
(max(origin_h, target_h), max(origin_w, target_w), 3), dtype=np.uint8
)
padded_img[:origin_h, :origin_w] = cp_img
x_offset, y_offset = 0, 0
if padded_img.shape[0] > target_h:
y_offset = random.randint(0, padded_img.shape[0] - target_h - 1)
if padded_img.shape[1] > target_w:
x_offset = random.randint(0, padded_img.shape[1] - target_w - 1)
padded_cropped_img = padded_img[
y_offset: y_offset + target_h, x_offset: x_offset + target_w
]
cp_bboxes_origin_np = adjust_box_anns(
cp_labels[:, :4].copy(), cp_scale_ratio, 0, 0, origin_w, origin_h
)
if FLIP:
cp_bboxes_origin_np[:, 0::2] = (
origin_w - cp_bboxes_origin_np[:, 0::2][:, ::-1]
)
cp_bboxes_transformed_np = cp_bboxes_origin_np.copy()
cp_bboxes_transformed_np[:, 0::2] = np.clip(
cp_bboxes_transformed_np[:, 0::2] - x_offset, 0, target_w
)
cp_bboxes_transformed_np[:, 1::2] = np.clip(
cp_bboxes_transformed_np[:, 1::2] - y_offset, 0, target_h
)
keep_list = box_candidates(cp_bboxes_origin_np.T, cp_bboxes_transformed_np.T, 5)
if keep_list.sum() >= 1.0:
cls_labels = cp_labels[keep_list, 4:5].copy()
box_labels = cp_bboxes_transformed_np[keep_list]
labels = np.hstack((box_labels, cls_labels))
origin_labels = np.vstack((origin_labels, labels))
origin_img = origin_img.astype(np.float32)
origin_img = 0.5 * origin_img + 0.5 * padded_cropped_img.astype(np.float32)
return origin_img.astype(np.uint8), origin_labels
if __name__ == '__main__':
pass
vocdataset=VocDataSet(
voc_root=r'E:\py_exercise\deep-learning-for-image-processing\pytorch_object_detection\faster_rcnn\taboca\Tobacco',
image_folder_name='JPEGImages'
)
dataset=MasaicDataset(
dataset=vocdataset,
)
next(iter(dataset))
|