百面机器学习
前言
虽然是临时抱佛脚,但是这些面试题对我这种小白来说还是学到很多。后面没有星星的问题并不是原书上的,因为面试也常顺便就归类了。
特征工程
为什么需要对数值类型的特征做归一化?$\bigstar$
归一化分为min-max和z-score归一化,前者只需要min和max即可归一,后者还需要均值和方差。效果也不一定会更好,但是通常z-score效果会更好一点 因为计算均值和方差更麻烦,对于需要梯度下降的算法如svm,线性回归,逻辑回归,神经网路等,在相同的学习率下,归一化能明显降低算法收敛速度。但决策树不适用

怎样处理类别型特征?$\bigstar\bigstar$
类别型特征分为两类:可比较和不可比较。
对于可比较类别型特征映射为0,1,2这种当然是没有问题。因为也保留了可比较这种特征
但是对于不可比较特征如男女,应该使用不可比较映射如onehot或二进制编码
现在二进制编码不常用等。对于onehot,如果特征过多会很冗余浪费空间可以用向量的稀疏表示节省空间。如[0,0,0,5,0,0,0,0,1]=>(10,[3,9],[5,1]),代表第3和9位上有个5和1
什么是组合特征?如何处理高维组合特征?$\bigstar\bigstar$
组合特征简单理解就是多个类别型特征对应一个label就是常见的excel文件。
我们通常处理都说分别使用onehot然后再拼接。比如:
有m个用户,n个物品,label为是否点击,拼接后对应的就是m+n+2维onehot向量(label看情况拼接)
但是对于互联网来说m和n太大了,尽管向量稀疏表示可以节省空间但是网络的训练参数确不能节省(m*n)。这个时候就需要矩阵分解了,将m*n分解乘m*k+k*n,k<<m,n。训练参数也大大减少
怎样有效地找到组合特征?$\bigstar\bigstar$
可以通过决策树帮助来寻找。
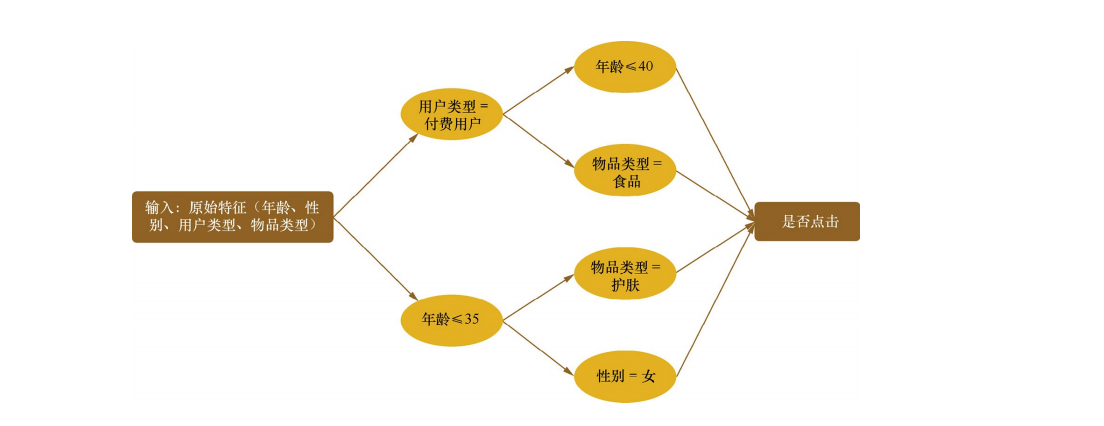 比如通过上面的决策树可以筛选出如下四个特征:
比如通过上面的决策树可以筛选出如下四个特征:
- 年龄<=35”且“性别=女”。
- 年龄<=35”且“物品类别=护肤”。
- 用户类型=付费”且“物品类型=食品”。
- 用户类型=付费”且“年龄<=40”。
那么下面这条信息可以被视为[1,1,0,0] :满足一二条不满足三四条
| 是否点击 | 年龄 | 性别 | 用户类型 | 物品类型 |
|---|---|---|---|---|
| 1 | 28 | 女 | 免费 | 护肤 |
有哪些文本表示模型?它们各有什么优缺点?$\bigstar\bigstar$
词袋模型
将整段文本以词为单位切分开[i,am,food], 然后每篇文章可以表示成一个长向量[[a,b,c],[aa,bb,cc],[aaa,bbb,ccc]],向量中的每一维代表一个单词,而该维对应的权重则反映了这个词在原文章中的重要程度。
可以看出权重计算极其关键,那如何计算权重呢?常用的是TF-IDF来计算文本的权重:TF-IDF=TF*IDF
TF为单词t在所有文章里的频率,IDF=$log \frac{文章总数}{包含单词t的文章总数+1}$。实际应用时可能不会直接按单词直接分割文本,而是可以word stemming(提取词干)和n-gram(提取短语)结合处理文本后再进行分割计算权重。
主题模型
LDA(隐迪利克雷模型)通过对所有文章训练然后将所有文章分为k个主题,每个主题n个关键词(k,n为参数)
深度学习模型和词嵌入模型
通过各种玄学的网络结构(如transformer)将文本映射为一系列向量,由于深度网络很大,能更深层的提取语义特征。
词嵌入模型作用也是和神经网络相同将词映射为向量最常用的就是谷歌提出的word2vec(本质也是个小型神经网路)
Word2Vec是如何工作的?它和LDA有什么区别与联系?$\bigstar\bigstar\bigstar$
word2vec是将一个词映射为一个向量,属于文本表示模型中的词嵌入模型
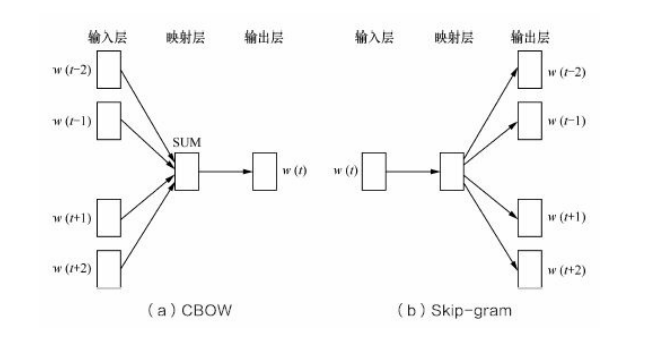
本质是一个神经网络,分为CBOW(根据前后预测中间的概率)和Skip-gram(通过中间预测前后的概率)两种实现方式,如上图
主题模型是一种基于概率图模型的生成式模型,其似然函数可以写成若干条件概率连乘的形式,其中包括需要推测的隐含变
量(即主题);而词嵌入模型一般表达为神经网络的形式,似然函数定义在网络的输出之上,需要通过学习网络的权重以得
到单词的稠密向量表示。
在图像分类任务中,训练数据不足会带来什么问题?如何缓解数据量不足带来的问题?$\bigstar\bigstar$
数据不足代表现验信息较少会导致训练集上效果可能还不错,测试集上蒙蔽(鲁棒性不强,过拟合)。
向增加模型泛化能力着手:
可以减少非线性层,增加惩罚项,调节dropout超参数等。
向增加现验信息着手,在保证特定信息条件下对数据进行扩充(Data Agumentation):
形态变换上可以:旋转,伸缩,裁剪(mask),平移,填充,
目标检测还可以重叠mosaic|mix up颜色饱和度等方面:噪声扰动,对颜色进行pca聚类得到三个主成分向量再在rgb添加主成分增量(可以参考Alex net)
图像空间上可以:在特征空间上进行变换如通用的SMOTE(Synthetic Minority Over-sampling Technique)算法。
增加样本上还可以使用Gan。
模型评估
准确率的局限性
精确率准确率召回率f1score就不再说了,值得一提的是可以找更好的评估指标,比如平均绝对百分比误差(Mean Absolute Percent Error,MAPE),它比RMSE的鲁棒性更好。
降维
如何定义主成分?从这种定义出发,如何设计目标函数使得降维达到提取主成分的目的?针对这个目标函数,如何对PCA问题进行求解 $\bigstar \bigstar$
主成分从数学上来说是降维后特征向量对应的特征值最大的为候选,但具体为哪些要通过人为设置的阈值来决定。降维的目的是我们想降维后的样本距离间尽可能大,投影尽可能分开并且样本离超平面尽可能近(回归的角度)。虽然有两个目标但是最后推导出的目标函数是相同的,下面以样本间距离尽可能大来推导:
首先我们需要将样本进行中心化,即$\sum_{i=1}^m X_i=0$,这样样本方差可以表示为$W^TXX^TW$,而且$W^TW=I$:
对于具有类别标签的数据,应当如何设计目标函数使得降维的过程中不损失类别信息?在这种目标下,应当如何进行求解?(手推LDA)$\bigstar \bigstar$
又pca我们知道,它不管类别标签,在对于有标签情况下根本无法使用。而我们可以从pca中受到启发,目标为类内距离尽可能小,类间距离尽可能大,下面用两类标签情况来演示(fisher 线性判别分析)多类则叫LDA
我们还是需要求解个超平面(二维是直线)W,满足上述条件:
假设低维类均值为$\bar\mu_i$,方差为$\bar\Sigma_i$,特征值为$y_i$,高维空间均值方差为$\mu_i,\Sigma_i$,特征值为x_i。目标函数为$max J_w=\frac{(\bar\mu_1-\bar\mu_2)^2}{\bar\Sigma_1^2+\bar\Sigma_2^2}$
投影后的类间距离可以表示为:
我们知道协方差矩阵可以写为:
故$L(w,\lambda)=W^T(\mu_1-\mu_2)(\mu_1-\mu_2)^TW+\lambda(W^T(\Sigma_1+\Sigma_2) W-c)$
$\frac{\partial L}{\partial w}=(\mu_1-\mu_2)(\mu_1-\mu_2)^TW+\lambda(\Sigma_1+\Sigma_2) W=0$
故$W=\frac{1}{\lambda}(\Sigma_1+\Sigma_2)^{-1}(\mu_1-\mu_2)R=(\Sigma_1+\Sigma_2)^{-1}(\mu_1-\mu_2)$
LDA和PCA作为经典的降维算法,如何从应用的角度分析其原理的异同?从数学推导的角度,两种降维算法在目标函数上有何区别与联系?
从应用角度来说,无监督使用PCA,因为PCA不涉及到类间距离,只人为类内距离越大隐含的信息越多,留下的主成分认为是最佳描述整体的特征(用于除去冗余信息如噪音)。而LDA需要标签来区别类间的距离,留下的主成分认为是每个类别的最佳描述特征。
从上面来看,LDA具有很大的优势,但由于涉及到不同领域(有监督和无监督)所整体来看还是各有千秋。
从算法流程来看,目标函数在一维下是相同的,且两者最后都是计算特征向量,非常相似,所以算法本质是相同的。
除了pca传统的的特征降维方法有哪些,特征选择方法有哪些
LDA(linear discriminat analysis),MDS(muti dimension scaling),LLE(local linear embeding)。
特征选择有过滤式选择,包裹式选择和嵌入式选择。
过滤式选择是先人为选择好特征子集再训练,模型与特征选择无关。
包裹式选择是选择与模型匹配的最好特征,即每次随机选择特征给模型进行训练,最后效果肯定比过滤式选择好,但是更耗费时间。
嵌入式选择是在训练的时候删去某个特征,然后对比效果,简单来说就是增加L1正则化,正则化项中有一项为0就是代表删去了特征。L1正则化比L2正则化稀疏解更多,即w中0更多。由下图可知:
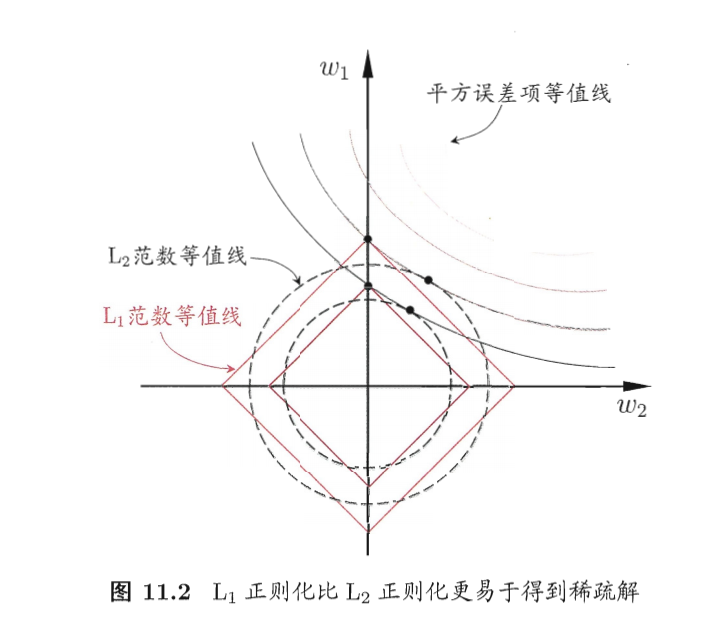
L1的等值线与误差等值线交点更多在坐标轴上,L2则是在象限中。
什么是流型学习,ISOmap和LLE的原理
流型是指局部具有欧式空间同胚的空间,流型学习是指低维欧式空间嵌入到高维仍具有欧式空间的特性,通过计算高维空间的距离并利用流型空间的特性可以局部映射到低维空间,然后再把局部映射关系推广到全局。因为具有距离不变性,常常用来数据可视化。比如已知n个城市飞机飞行的距离(高维空间的距离),我们可以用ISOmap将城市映射到二维空间并可视化。
ISOmap(isometric map)等度量映射:实际上是将MDS在应用方向的另一个名称,算法本质就是MDS。具体步骤:已知高维空间坐标,计算高维空间两两距离,然后使用MDS映射到低维空间得到低维空间的坐标。
由于ISOmap只能离线处理(每次需要等数据输入完后再计算,且不能用于预测),实际使用并不是很方便,比较流行的方法:
通过n个点高维坐标输入,低维坐标作为输出训练一个回归器,当第n+1个点输入时使用回归器预测n+1点低维的坐标。
但是仍不能很好解决问题。
LLE(Local linear embedding)局部线性嵌入:与保持空间距离不变不同LLE旨在保持空间的线性性:假设高维空间的n节点可以用k近邻个节点线性表示,那么我们希望低维空间的n节点仍然有这个性质(组合系数w不变)。
即先后优化两个Loss:
第一个目标函数求出组合系数w第二个目标函数求出低维坐标y。
无监督学习
K均值算法的优缺点是什么?如何对其进行调优?$\bigstar \bigstar\bigstar$
优点:
- 算法足够高效,复杂度低。
- 局部最优常常也能满足需求。
缺点:
- 离群值处理不太行。
- 对于数据分布不均匀处理不当。
- 不太适用离散分布。
- 初始点选择很重要。
- K值选择也很重要。
调优:
- 适用中位数代替平均数(k-media)和对数据进行预处理,能很好减少离群点的影响
- 多次尝试初始值可以缓解初始值的影响或适用Kmeans++来弥补。
- 可以通过手肘法或Gap Statistic方法选择K值。
- 通过核函数映射到高维(核kmeans)达到更准确的聚类结果
高斯混合模型的核心思想是什么?它是如何迭代计算的$\bigstar\bigstar$
高斯混合模型和核心是假设数据是高斯分布生成出来的,但我们不知道均值方差和权重,故先假设已知再通过EM算法求出最合适(似然函数变化稳定)的均值方差和权重。
以聚类问题为例,假设没有外部标签数据,如何评估两个聚类算法的优劣?$\bigstar\bigstar\bigstar$
SVM
推导SVM
我们需要一个超平面将两类点分隔开,且不同类别的点到直线距离都尽可能大。$max {min J(w)=\frac{|w^Tx+b|}{||w||}}$
设标签类别为$y_i$,由于对于正类$y_i>0$且$w^Tx+b>=1$对于负类$y_i<0$, $w^Tx+b<=-1$:故点到直线距离可去掉绝对值统一为$y_i*(w^Tx+b)$。
对于$|w^Tx+b|=1$这两条线,我们称为支持向量,如果点线性可分(下面讨论线性可分支持向量机),则上述目标函数可转换为两个支持向量距离最长即:
约束条件为:w,x为列向量
拉格朗日函数:
此方程组的限制条件(又称KKT条件)为:
其中$a_i$为KKT乘数,如何判断KKT乘数的符号也有讲究:对于min问题,乘数项应该异号对于max问题,乘数项应该同号。
KKT条件实际上并不是条件,而是前提,存在不等式方程组求解时,如果可以求解则必须满足KKT条件,此时通过求解的拉格朗日方程组也叫KKT方程组。自己理解,不一定对
对上式求偏导:
带入拉格朗日方程:
其实这里已经可以求解出具体的w和b了。但是不同方法结果不同,我这里采用SMO方法求解(具体SMO还是得看书,比较麻烦)。
选取$ai,a_j$,其余$a_k$看成常数,$a_iy_i+a_jy_j=\sum{k\neq i,j}^ma_ky_k$
用$ai$表示$a_j$,对消去$a_j$的L求导可求出$a{i}$。
关于b,我们可以通过支持向量的约束来求解$ys(\sum{i\in S}a_iy_ix_i^Tx_s+b)=1$
但每一个支持向量的点都能求出一个b,这里直接暴力去平均即可得到$b=\frac{1}{|S|}\sum{i \in S} (y_s-\sum{i\in S}a_iy_ix_i^Tx_s)$
在空间上线性可分的两类点,分别向SVM分类的超平面上做投影,这些点在超平面上的投影仍然是线性可分的吗? $\bigstar \bigstar\bigstar$
结论:对于任意线性可分的两组点,它们在SVM分类的超平面上的投影都是线性不可分的。
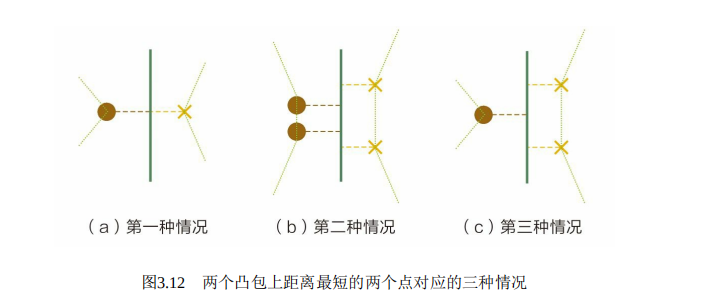
该问题可以通过凸优化理论中的超平面分离定理(Separating Hyperplane Theorem,SHT)更加轻巧地解决。该定理描述的是,对于不相交的两个凸集,存在一个超平面,将两个凸集分离。对于二维的情况,两个凸集间距离最短两点连线的中垂线就是一个将它们分离的超平面。
通过以上定理,我们可以将两组点先各自求凸包,可以发现分割两个凸包的超平面就是SVM所得出的支持向量(二维情况下就是两个凸包距离最小点的中垂线)。
遂有图3.12三种情况,对于任意一种情况,其投影都线性不可分。(在二维情况上就是两个点集投影在支持向量上,然后再用一条线将他们分开,显然不可能)
Logistic 回归
逻辑回归相比于线性回归,有何异同?$\bigstar \bigstar$
在此之前我们要知道广义的线性回归:满足$y=g(w^Tx+b)$,其中g为可微函数。
由于人们在考虑回归时也想用回归来进行分类任务,灵机一动想到阶跃函数,但是阶跃函数不可微,遂使用对数几率函数(Logistic Function)$y=\frac{1}{1+e^{-z}}$函数来代替,这个函数是Sigmod函数的一种只要是S形状的都是sigmod函数。
我们将logistic function代替广义回归式中的g并做变换则有:
若将y视为x为正例的可能性,1-y则是x为反例的可能性,他们比值就是几率反映了相对可能性,这就是对数几率回归(logistic regression)的由来。
然而逻辑回归的最优化函数与线性回归截然不同:
通过上述有$p(y=k|x)=e^{w^x+b}$,要求分类错误最小则最大化对数似然函数,估计w和b:
则也是最小化$-L(w,b)$即等价于最小化CrossEntryloss
总结以下,逻辑回归与线性回归相比:
- 一个用于分类,一个用于回归,使用方向完全不同。
- 线性回归是求解均方差最小,而logistic regression是求解最大似然函数。
- 但他们求解方法都可以使用梯度下降法求解。
逻辑回归为什么不使用MSE作为loss
假设这是一个二分类,预测类别为0,实际类别为1。显然这个分类器完全错误,但是MSE loss仅仅为1!!!。对比交叉熵:
其次,MSE会出现梯度消失现:
当$h(s_i)$为1或0时$L_w’\rightarrow0$,出现梯度消失。
更重要的是,它不是一个非凸函数,要知道梯度下降需要如果优化非凸函数并不能找到全局最优虽然一般也找不到:
当$h(s_i)\in (0,1),y=0$时,$L’’$由$3h(s_i)^2-2h(s_i)$决定,这个在$h\in (0,1)$有正有负,所以$L_w$非凸。
当使用逻辑回归处理多标签的分类问题时,有哪些常见做法,分别应用于哪些场景,它们之间又有怎样的关系?$\bigstar \bigstar \bigstar$
对于每类只有一个标签的多分类,我们假设每类都符合几何分布:
一般来说,多项逻辑回归具有参数冗余的特点,即将同时加减一个向量后预测结果不变。特别地,当类别数为2时。
令所有参数减去$\theta_1$,则有
整理后发现与逻辑回归相同。因此,多标签分类逻辑回归实际上是二分类的一种拓展。而多元逻辑回归式子又叫softmax函数。
决策树
决策树有哪些常用的启发函数?$\bigstar \bigstar$
IDF3(Iterater dichotomister 3) 最大信息增益:
数据集D的经验熵:$H(D)=-\sum_{i=1}^SP(w_i|t)*log_2P(w_i|t)$
对于特征A经验条件熵$H(D|A)=\sum_i^n \frac{|D_i|}{|D|}H(D_i)$
判定停止条件为:$max {g(D)}=H(D)-H(D|A)$
C4.5 最大信息增益比:
判断停止条件为$g_r(D)=\frac{g(D)}{H_A(D)}$
其中取值熵:$HA(D)=\sum{i=1}^{n}\frac{|D_i|}{|D|}log_2\frac{|D_i|}{|D|}$
CART(Classification And Regression Tree) 最大基尼系数:
$G(D)=\sum{i=1}^{n}p(x_i)(1-p{xi})=1-\sum{i=1}^{n}p(xi)^2=1-\sum{i=1}^n(\frac{|C_k|}{|D|})^2$ k为所有特征种类如年龄性别等
代表从数据集D中随机抽取两个样本,其类别标记不一致的概率。因此G(D)越小,则数据集D的纯度越高。
特征A的基尼系数$G(D|A)=\sum_{i=1}^n\frac{|D_i|}{|D|}G(D_i)$,n为特征A的种类如年龄中的老少等。
划分点就是最小特征基尼系数。
首先,ID3是采用信息增益作为评价标准,会倾向于取值较多的特征。因为,信息增益反映的是给定条件以后不确定性减少的程度,特征取值越多就意味着确定性更高,也就是条件熵越小,信息增益越大。这导致泛化能力很弱。因此,C4.5实际上是对ID3进行优化,通过引入信息增益比,一定程度上对取值比较多的特征进行惩罚,避免ID3出现过拟合的特性,提升决策树的泛化能力。
其次,从样本类型的角度,ID3只能处理离散型变量(对于长度这种就不能了),而C4.5和CART都可以处理连续型变量。C4.5处理连续型变量时,通过对数据排序之后找到数值不同的点,根据切分点把连续属性转换为布尔型,从而将连续型变量转换多个取值区间的离散型变量。而对于CART,由于其构建时每次都会对特征进行二值划分,因此可以很好地适用于连续性变量。
从应用角度,ID3和C4.5只能用于分类任务,而CART可以用于回归任务(回归树使用最小平方误差准则)。
此外,从实现细节、优化过程等角度:ID3对样本特征缺失值比较敏感,而C4.5和CART可以对缺失值进行不同方式的处理;ID3和C4.5可以在每个结点上产生出多叉分支,且每个特征在层级之间不会复用,而CART每个结点只会产生两个分支,因此最后会形成一颗二叉树,且每个特征可以被重复使用;ID3和C4.5通过剪枝来权衡树的准确性与泛化能力,而CART直接利用全部数据发现所有可能的树结构进行对比。
如何对决策树进行剪枝? $\bigstar \bigstar \bigstar$
预剪枝(pre-pruning):
- 做数据集划分,每次生成分支的时候通过验证集算损失,损失最小时则停止。
- 设置固定深度,到达深度时停止增长。
- 设置熵变化量阈值,熵变化量小于阈值时停止
- 信息增益显著性分析,如果当前增益不显著则停止划分。通常使用卡方检验。
后剪枝(post-pruning):
基于最小分类错误(Reduced Error Pruning,REP):如果去掉该枝干错误率减小则剪枝。
最小长度准则:对决策树编码,剪枝得到编码最短的决策树(不是很明白)
基于代价和复杂性综合考虑(Cost Complexity Pruning,CCP):如果去掉该枝干,综合错误率和复杂性综合考虑是否剪枝。
设在t处剪枝的误差为:$\alpha=\frac{R(t)-R(Tt)}{|L(t)|-1}$
L(t)代表以t节点为根的叶子数总数,R(t)代表t
优化算法
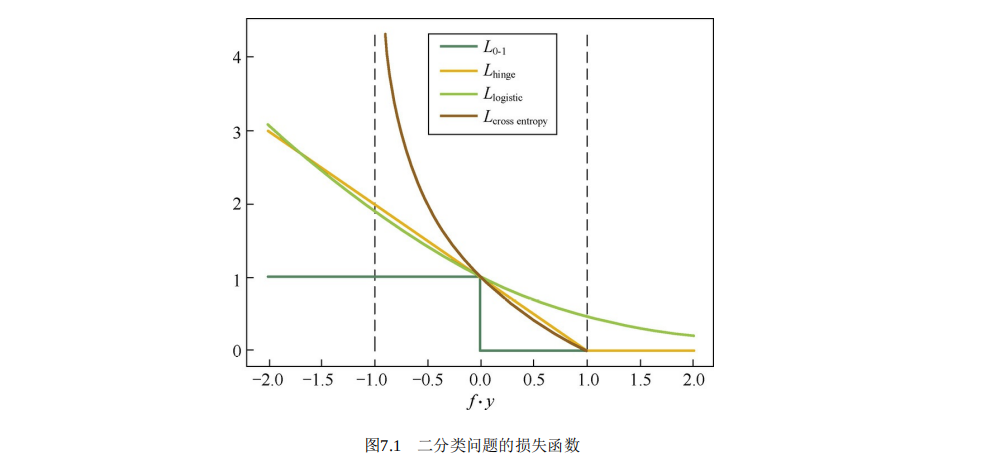
监督学习的损失函数 $\bigstar$
最基础的肯定是0-1 loss,预测正确为0,错误为1,但是它不平滑不可导,就有了hinge loss替代它:
同样,预测正确时损失为0,预测错误是hinge loss 是0-1 loss的凸上界。但是显然,某一点仍然不可导不能用梯度下降法进行优化。
0-1 loss 另一个替代就是logsitic loss:
它处处可导,但是在预测正确时仍有损失,还有一种就是交叉熵损失:
四种函数图像如下所示
本文链接:https://dummerfu.top/p/44332.html
版权声明: 本博客所有文章除特别声明外,均采用CC BY-NC-SA 4.0许可协议 转载请注明出处!



